Cloud Computing
-
Platformonomics TGIF #128: May 29, 2026

Platformonomics TGIF is a weekly roll-up of links, comments on those links, and perhaps a little too much tugging on my favorite threads. Get Platformonomics Updates By Email 50-50 chance of a newsletter next week. Might be too busy preparing for the Cleveland visit. Still waiting to hear whether Seattle’s Mayor and Washington’s Governor are…
-
Platformonomics TGIF #125: May 1, 2026

Platformonomics TGIF is a weekly roll-up of links, comments on those links, and perhaps a little too much tugging on my favorite threads. Get Platformonomics Updates By Email Service has been restored! This May Day we celebrate basic financial controls, one of the cornerstones of advanced civilization! My Writing Follow the CAPEX: Q1 2026 Scoreboard…
-
Follow the CAPEX 2025 Retrospective
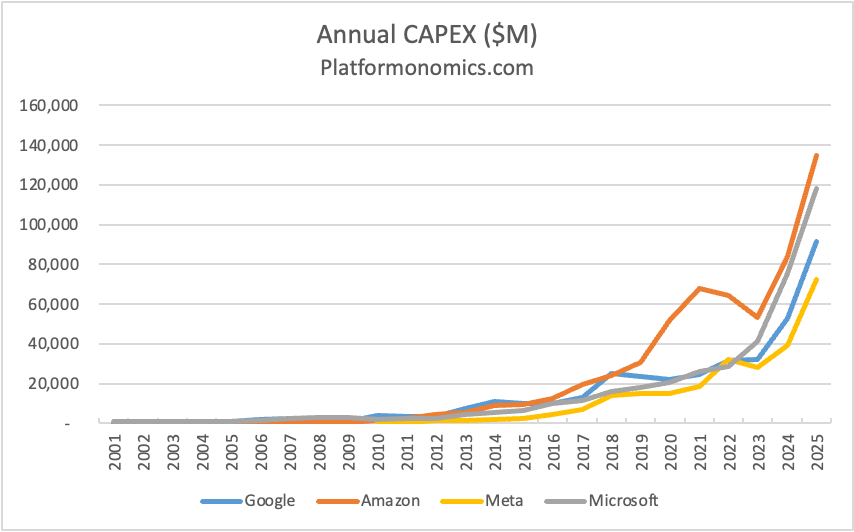
Tl;dr CAPEX Go Up! Up Up Up! Previous retrospectives: 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024 plus earlier/other CAPEX musings. This is my tenth annual CAPEX (capital expenditures) retrospective. The fascination began earlier, as an asset-oblivious software guy confronting an alien lifeform of spending on physical property, plant and equipment. CAPEX separated the…