Microsoft
-
Follow the CAPEX: Q1 2026 Scoreboard

All four hyperCAPEX companies reporting the same day makes for a big day in the world’s biggest game! Our four hyperCAPEX companies spent over $133 billion on CAPEX in Q1, collectively up 4% from Q4 and up 72% from a year ago. 2025 Actual CAPEX 2026 Guidance CAPEX (Jan ’26) 2026 Guidance CAPEX (Apr ’26)…
-
Platformonomics TGIF #118: February 27, 2026

Platformonomics TGIF is a weekly roll-up of links, comments on those links, and perhaps a little too much tugging on my favorite threads. Get Platformonomics Updates By Email CAPEX retrospected! Onward! My Writing Follow the CAPEX 2025 Retrospective Letting an LLM take a shot at writing this piece was good for my sense of future…
-
Follow the CAPEX 2025 Retrospective
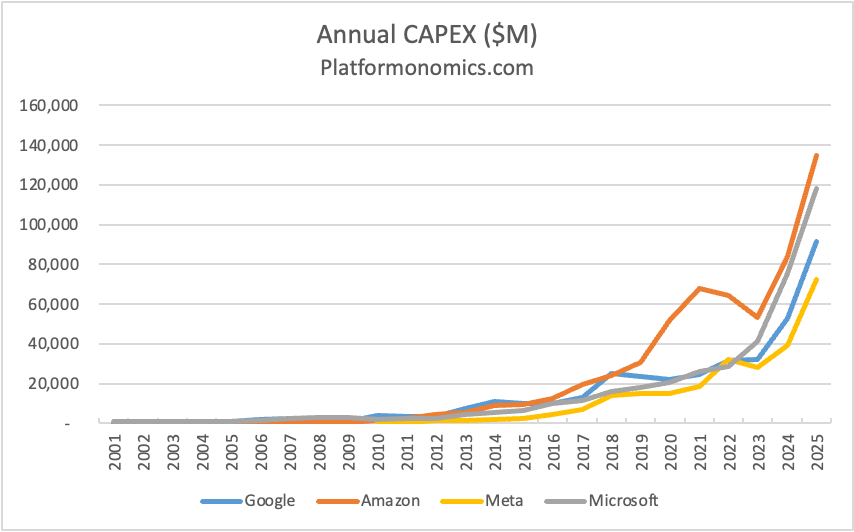
Tl;dr CAPEX Go Up! Up Up Up! Previous retrospectives: 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024 plus earlier/other CAPEX musings. This is my tenth annual CAPEX (capital expenditures) retrospective. The fascination began earlier, as an asset-oblivious software guy confronting an alien lifeform of spending on physical property, plant and equipment. CAPEX separated the…